第三章 流
Java 8 对核心类库的改进主要包括集合类的 API 和新引入的流 (Stream)。流使程序员得以站在更高的抽象层次上对集合进行操作。
3.1 从外部迭代到内部迭代
传统使用 for 循环计算来自伦敦的艺术家人数
int count = 0;
for (Artist artist : allArtists) {
if (artist.isFrom("London")) {
count++;
}
}
这样的操作可行,但存在几个问题:
- 需要写很多样板代码
- 将
for循环改造成并行方式运行也很麻烦 - 无法流畅传达程序员的意图,单一的 for 循环,问题不大,多重嵌套循环的大代码库时,负担就重了。
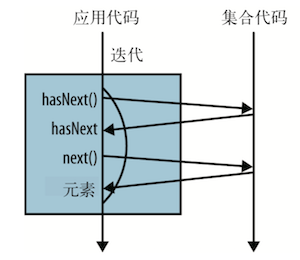
for 循环其实是一个封装了迭代的语法糖,首先调用 iterator 方法,产生一个新的 Iterator 对象,进而控制整 个迭代过程,这就是外部迭代,可简单理解为需要手动在业务代码中写迭代过程。它从本质上来讲是一种串行化操作。总体来看,使用 for 循环会将行为和方法混为一谈。
int count = 0;
Iterator<Artist> iterator = allArtists.iterator();
while(iterator.hasNext()) {
Artist artist = iterator.next();
if (artist.isFrom("London")) {
count++;
}
}
使用内部迭代计算来自伦敦的艺术家人数,内部迭代可简单理解为迭代过程是在函数库内部。
//该方法不是返回一个控制迭代的 Iterator 对象,而是返回内部迭代中的相应接口:Stream。
long count = allArtists.stream()
.filter(artist -> artist.isFrom("London"))
.count();
3.2 实现机制
及早求值方法与惰性求值方法
如下代码
allArtists.stream()
.filter(artist -> {
System.out.println(artist.getName());
return artist.isFrom("London"); });
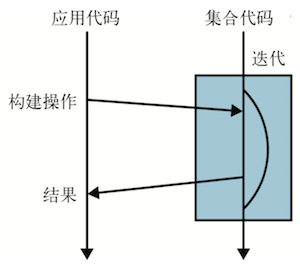
这行代码并未做什么实际性的工作,filter 只刻画出了 Stream,但没有产生新的集合。像 filter 这样只描述 Stream,最终不产生新集合的方法叫作 惰性求值方法;而像 count 这样 最终会从 Stream 产生值的方法叫作 及早求值方法。运行这段代码,程序不会输出任何信息
long count = allArtists.stream()
.filter(artist -> {
System.out.println(artist.getName());
return artist.isFrom("London"); })
.count();
运行上述程序,命令行里输出复合条件的值。
-
判断一个操作是惰性求值还是及早求值很简单:只需看它的返回值。如果返回值是
Stream, 那么是惰性求值;如果返回值是另一个值或为空,那么就是及早求值。使用这些操作的理 想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果,这正是 它的合理之处。 -
整个过程和建造者模式有共通之处。建造者模式使用一系列操作设置属性和配置,最后调 用一个
build方法,这时,对象才被真正创建。 -
为什么要区分惰性求值和及早求值? 只有在对需要什么样的结果和操作有了更多了解之后,才能更有效率地进行计算。例如,如果要找出大于
10的第一个数 字,那么并不需要和所有元素去做比较,只要找出第一个匹配的元素就够了。这也意味着 可以在集合类上级联多种操作,但迭代只需一次。
常用的流操作
3.3.1 collect(toList())
collect(toList()) 方法由 Stream 里的值生成一个列表,是一个及早求值操作。
List<String> collected = Stream.of("a","b","c")
.collect(Collectors.toList());
assertEquals(Arrays.asList("a","b","c"),collected);
由于很多 Stream 操作都是惰性求值,因此调用 Stream 上一系列方法之后,还需要最后再 调用一个类似 collect 的 及早求值方法。
3.3.2 map
如果有一个函数可以将一种类型的值转换成另外一种类型,map 操作就可以 使用该函数,将一个流中的值转换成一个新的流。
- 使用
for循环将字符串转换为大写
List<String> collected = new ArrayList<>();
for (String string : asList("a", "b", "hello")) {
String uppercaseString = string.toUpperCase();
collected.add(uppercaseString);
}
- 使用
map操作将字符串转换为大写形式
List<String> collected = Stream.of("a", "b", "hello")
.map(string -> string.toUpperCase())
.collect(toList());
assertEquals(Arrays.asList("A","B","HELLO"),collected);
传给map的lambda表达式必须是Function的一个实例,参数和返回值不用是同一种类型。
3.3.3 filter
上面的例子已经可以看到,filter是用来过滤几个元素的,filter返回的是stream,因此也是 惰性求值方法
- 过滤包含指定子串的字符串
List<String> collected = Stream.of("a","b","hello","asdabc","ab")
.filter(str -> str.contains("ab"))
.collect(Collectors.toList());
assertEquals(Arrays.asList("asdabc","ab"),collected);
filter接受一个函数作为参数,该函数必须是Predicate的一个实例,因此返回值必须是true或false
3.3.4 flatMap
flatMap 方法可用 Stream 替换值,然后将多个 Stream 连接成一个 Stream
- 包含多个列表的
Stream
List<Integer> together = Stream.of(Arrays.asList(1, 2), Arrays.asList(3, 4))
.flatMap(numbers -> numbers.stream())
.collect(Collectors.toList());
assertEquals(Arrays.asList(1, 2, 3, 4), together);
调用 stream 方法,将每个列表转换成 Stream 对象,其余部分由 flatMap 方法处理。 flatMap 方法的相关函数接口和 map 方法的一样,都是 Function 接口,只是方法的返回值 限定为 Stream 类型罢了
3.3.5 max和min
使用 Stream 查找长度最短的字符串
String min = Stream.of("123", "4567","89101112")
.min(Comparator.comparing(str -> str.length()))
.get();
System.out.println(min);
查找 Stream 中的最大或最小元素,首先要考虑的是用什么作为排序的指标,这里使用字符串长度作为排序的指标。为了让Stream对象按照曲目长度进行排序,需要传给它一个Comparator对象。Java 8 提 供了一个新的静态方法comparing,使用它可以方便地实现一个比较器。放在以前,我们 需要比较两个对象的某项属性的值,现在只需要提供一个存取方法就够了
3.3.6 通用模式
上面找最小值的如果不使用Lambda表达式,最一般的for循环遍历代码如下:
List<String> strs = Arrays.asList("123", "4567","89101112");
String minStr = strs.get(0);
for(String str : strs){
if(str.length() < minStr.length()){
minStr = str;
}
}
assertEquals(strs.get(0),minStr);
以上这种模式总结一下,可称为reduce模式,更一般的代码形式如下:
Object accumulator = initialValue;
for(Object element : collection) {
accumulator = combine(accumulator, element);
}
首先赋给 accumulator 一个初始值:initialValue,然后在循环体中,通过调用 combine 函数,拿 accumulator 和集合中的每一个元素做运算,再将运算结果赋给 accumulator,最后 accumulator 的值就是想要的结果。
3.3.7 reduce
reduce 操作可以实现从一组值中生成一个值。在上述例子中用到的 count、min 和 max 方 法,因为常用而被纳入标准库中。事实上,这些方法都是 reduce 操作。
- 使用
reduce求和
int sum = Stream.of(1,2,3,4,5,6)
.reduce(0,(acc,element)->acc+element);
assertEquals(21,sum);
Lambda 表达式的返回值是最新的 acc,是上一轮 acc 的值和当前元素相加的结果。reducer 的类型是第 2 章已介绍过的 BinaryOperator
- 展开 reduce 操作
BinaryOperator<Integer> accumulator = (acc, element) -> acc + element;
int count = accumulator.apply(
accumulator.apply(
accumulator.apply(0, 1),
2),
3);
BinaryOperator是Function interface(包含唯一接口apply),Lambda表达式实际上就是实现了apply函数,因此我们也可以显示调用apply方法。
3.3.8 整合操作
Stream 接口的方法如此之多,有时会让人难以选择,本节将举例说明如何将问题分解为简单的 Stream 操作。
第一个要解决的问题是,找出某张专辑上所有乐队的国籍。艺术家列表里既有个人,也有 乐队。利用一点领域知识,假定一般乐队名以定冠词 The 开头。当然这不是绝对的,但也差不多。
首先, 可将这个问题分解为如下几个步骤。
- 找出专辑上的所有表演者。
- 分辨出哪些表演者是乐队。
- 找出每个乐队的国籍。
- 将找出的国籍放入一个集合。
List<Artist> artists = Arrays.asList(new Artist("aert", "China"), new Artist("adasda", "USA"),
new Artist("qweqvsf", "Jap"), new Artist("The askjkj", "England"));
List<String> nations = artists.stream()
.filter(str -> str.getName().startsWith("The"))
.map(art -> art.getFrom())
.collect(Collectors.toList());
assertEquals(Arrays.asList("England"),nations);
这个例子将 Stream 的链式操作展现得淋漓尽致,调用 filter 和 map 方法都 返回 Stream 对象,因此都属于惰性求值,而 collect 方法属于及早求值。map 方法接受一 个 Lambda 表达式,使用该 Lambda 表达式对 Stream 上的每个元素做映射,形成一个新的 Stream。
3.4 重构遗留代码
- 本节将举例说明如何将一段使用循环进行集合操作的 代码,重构成基于
Stream的操作。
假定选定一组专辑,找出其中所有长度大于 1 分钟的曲目名称。下面是遗留代码,首先 初始化一个 Set 对象,用来保存找到的曲目名称。然后使用 for 循环遍历所有专辑,每次 循环中再使用一个 for 循环遍历每张专辑上的每首曲目,检查其长度是否大于 60 秒,如 果是,则将该曲目名称加入 Set 对象。
public static Set<String> findLongTracks(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
for (Album album : albums) {
for (Track track : album.getTracks()) {
if (track.getLength() > 60) {
String name = track.getSongName();
trackNames.add(name);
}
}
}
return trackNames;
}
使用流来重构该段代码的方式很多,下面介绍的只是其 中一种。事实上,对 Stream API 越熟悉,就越不需要细分步骤。之所以在示例中一步一步地重构,完全是出于帮助大家学习的目的,在工作中无需这样做。
- 第一步要修改的是
for循环。首先使用Stream的forEach方法替换掉for循环,但还是暂时保留原来循环体中的代码,这是在重构时非常方便的一个技巧。
public static Set<String> findLongTracksStep1(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.forEach(album -> {
album.getTracks()
.forEach(track -> {
if (track.getLength() > 60) {
trackNames.add(track.getSongName());
}
});
});
return trackNames;
}
- 重构的第二步:找出长度大于 1 分钟的曲目
public static Set<String> findLongTracksStep2(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.forEach(album -> {
album.getTracksStream()
.filter(track -> track.getLength() > 60)
.map(track -> track.getSongName())
.forEach(name -> trackNames.add(name));
});
return trackNames;
}
- 重构外层循环
public static Set<String> findLongTracksStep3(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.flatMap(album -> album.getTracksStream())
.filter(track -> track.getLength() > 60)
.map(track -> track.getSongName())
.forEach(name -> trackNames.add(name));
return trackNames;
}
上面的代码中使用一组简洁的方法调用替换掉两个嵌套的 for 循环,看起来清晰很多。然 而至此并未结束,仍需手动创建一个 Set 对象并将元素加入其中,但我们希望看到的是整 个计算任务由一连串的 Stream 操作完成。
- 重构手动创建一个
Set对象并将元素
public static Set<String> findLongTracksStep4(List<Album> albums) {
return
albums.stream()
.flatMap(album -> album.getTracksStream())
.filter(track -> track.getLength() > 60)
.map(track -> track.getSongName())
.collect(Collectors.toSet());
}
简而言之,选取一段遗留代码进行重构,转换成使用流风格的代码。最初只是简单地使用 流,但没有引入任何有用的流操作。随后通过一系列重构,最终使代码更符合使用流的风 格。在上述步骤中我们没有提到一个重点,即编写示例代码的每一步都要进行单元测试,保证代码能够正常工作。重构遗留代码时,这样做很有帮助。
3.5 多次调用流操作
用户也可以选择每一步强制对函数求值,而不是将所有的方法调用链接在一起,但是,最 好不要如此操作。展示了如何用如上述不建议的编码风格来找出专辑上所有演出乐 队的国籍。
- 误用 Stream 的例子
List<Artist> musicians = album.getMusicians()
.collect(toList());
List<Artist> bands = musicians.stream()
.filter(artist -> artist.getName().startsWith("The"))
.collect(toList());
Set<String> origins = bands.stream()
.map(artist -> artist.getNationality())
.collect(toSet());
- 符合 Stream 使用习惯的链式调用
Set<String> origins = album.getMusicians()
.filter(artist -> artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(toSet());
- 第一个例子和流的链式调用相比有如下缺点
- 代码可读性差,样板代码太多,隐藏了真正的业务逻辑;
- 效率差,每一步都要对流及早求值,生成新的集合;
- 代码充斥一堆垃圾变量,它们只用来保存中间结果,除此之外毫无用处;
- 难于自动并行化处理。
3.6 高阶函数
高阶函数是指接受另外一个函数作为参数,或返回一个函数的函数。高阶函数不难辨认:看函数签名就够了。如果函数的参数列表里包含函数接口,或该函数返回一个函数接口,那么该函数就是高阶函数。
map 是一个高阶函数,因为它的 mapper 参数是一个函数。事实上,本章介绍的 Stream 接口 中几乎所有的函数都是高阶函数。之前的排序例子中还用到了 comparing 函数,它接受一 个函数作为参数,获取相应的值,同时返回一个 Comparator。Comparator 可能会被误认为 是一个对象,但它有且只有一个抽象方法,所以实际上是一个函数接口。
事实上,可以大胆断言,Comparator 实际上应该是个函数,但是那时的 Java 只有对象,因 此才造出了一个类,一个匿名类。成为对象实属巧合,函数接口向正确的方向迈出了一步。
3.7 正确使用Lambda表达式
本章介绍的概念能够帮助用户写出更简单的代码,因为这些概念描述了数据上的操作,明确了要达成什么转化(理解为大部分操作都可以转化成接口函数,比如:Predicate、Function、Consume等等),而不是说明如何转化。这种方式写出的代码,潜在的缺陷更少,更直接地表达了程序员的意图。
没有副作用的函数不会改变程序或外界的状态。本书中的第一个 Lambda 表达式示例是有副作用的,它向控制台输出了信息——一个可观测到的副作用。下面的代码有没有副作用?
private ActionEvent lastEvent;
private void registerHandler() {
button.addActionListener((ActionEvent event) -> {
this.lastEvent = event;
});
}
以上代码有副作用,只要是给类的成员变量赋值就肯定会改变类的状态,那么就一定有副作用。
无论何时,将 Lambda 表达式传给 Stream 上的高阶函数,都应该尽量避免副作用。唯一的 例外是 forEach 方法,它是一个终结方法。
这节理解的不是很透彻,需要后续重点关注一下
3.8 要点回顾
- 内部迭代将更多控制权交给了集合类。
- 和
Iterator类似,Stream是一种内部迭代方式。 - 将
Lambda表达式和Stream上的方法结合起来,可以完成很多常见的集合操作。
3.9 练习
-
常用流操作。实现如下函数: a. 编写一个求和函数,计算流中所有数之和。例如,int addUp(Stream
numbers); public static int addUp(Stream<Integer> numbers) { return numbers.reduce(0, (acc, num) -> acc + num); }b. 编写一个函数,接受艺术家列表作为参数,返回一个字符串列表,其中包含艺术家的姓名和国籍;
public static List<String> getArtistNameAndNation(List<Artist> artists){ return artists.stream() .flatMap(artist -> Stream.of(artist.getName(),artist.getFrom())) .collect(Collectors.toList()); }这个题目刚开始没理解对直接把国籍生成的List追加到了名称的结果List,这里主要还是
flatMap的用法 可用Stream替换值,然后将多个Stream连接成一个Stream。c. 编写一个函数,接受专辑列表作为参数,返回一个由最多包含 3 首歌曲的专辑组成的列表。
public static List<Album> filterAlbum(List<Album> albums){ return albums.stream() .filter(album -> album.getTracks().size() <= 3) .collect(Collectors.toList()); } -
迭代。修改如下代码,将外部迭代转换成内部迭代:
int totalMembers = 0;
for (Artist artist : artists) {
Stream<Artist> members = artist.getMembers();
totalMembers += members.count();
}
- 修改后代码
artists.stream()
.flatMap(artist -> artist.getMembers())
.reduce(0,(acc,members) -> member.count())
-
求值。根据
Stream方法的签名,判断其是惰性求值还是及早求值。 a. boolean anyMatch(Predicate<? super T> predicate);//及早求值 b. Streamlimit(long maxSize);//惰性求值 -
高阶函数。下面的
Stream函数是高阶函数吗?为什么? a. boolean anyMatch(Predicate<? super T> predicate); //高阶函数,因为参数传递是一组操作(函数) b. Streamlimit(long maxSize);//非高阶函数,返回值或参数非一组操作 -
纯函数。下面的 Lambda 表达式有无副作用,或者说它们是否更改了程序状态?
x->x+1//无副作用,未改变程序的状态
示例代码如下所示:
AtomicInteger count = new AtomicInteger(0);
List<String> origins = album.musicians()
.forEach(musician -> count.incAndGet();)
a. 上述示例代码中传入 forEach 方法的 Lambda 表达式。//它是一个终结方法
- 计算一个字符串中小写字母的个数(提示:参阅 String 对象的 chars 方法)。
public static long countLowercase(String str){
return str.chars()
.filter(ch -> ch >= 'a' && ch <= 'z')
.count();
}
- 在一个字符串列表中,找出包含最多小写字母的字符串。对于空列表,返回
Optional<String>对象。
public static Optional<String> mostUpcaseStr(List<String> strs) {
return strs.stream()
.max(Comparator.comparing(str -> str.chars()
.filter(ch -> ch >= 'a' && ch <= 'z')
.count()));
}
思路是利用max方法,需要自定义比较函数
3.10 进阶练习
简单看了一下题目,感觉完全没思路(-__-!!),看了一下系统的默认实现,也是没怎么看懂,只能留着过几天再来看一下
-
只用
reduce和Lambda表达式写出实现Stream上的map操作的代码,如果不想返回Stream,可以返回一个List。 -
只用
reduce和Lambda表达式写出实现Stream上的filter操作的代码,如果不想返回Stream,可以返回一个List。
本文由 zealzhangz 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2018/10/13 16:17
