第8章 设计和架构的原则
本章旨在帮助大家写出优秀的程序,我会给出一些良好的设计原则和模式,在此基础之上,就能开发出可维护且十分可靠的程序。我们不光会用到 JDK 提供的崭新类库,而且会教大家如何在自己的领域和应用程序中使用 Lambda 表达式。
8.1 Lambda表达式改变了设计模式
设计模式是人们熟悉的另一种设计思想,它是软件架构中解决通用问题的模板。如果碰到 一个问题,并且恰好熟悉一个与之适应的模式,就能直接应用该模式来解决问题。从某种 程度上来说,设计模式将解决特定问题的最佳实践途径固定了下来。
当然,没有永远的最佳实践。以曾经风靡一时的单例模式为例,该模式确保只产生一个对象实例。在过去十年中,人们批评它让程序变得更脆弱,且难于测试。敏捷开发的流行, 让测试显得更加重要,单例模式的这个问题把它变成了一个反模式:一种应该避免使用的模式。
本书的重点并不是讨论设计模式如何变得过时,相反,我们讨论的是如何使用 Lambda 表达式,让现有设计模式变得更好、更简单,或者在某些情况下,有了不同的实现方式。 Java 8 引入的新语言特性是所有这些设计模式变化的推动因素。
8.1.1 命令者模式
命令者是一个对象,它封装了调用另一个方法的所有细节,命令者模式使用该对象,可以 编写出根据运行期条件,顺序调用方法的一般化代码。命令者模式中有四个类参与其中,如下图所示:
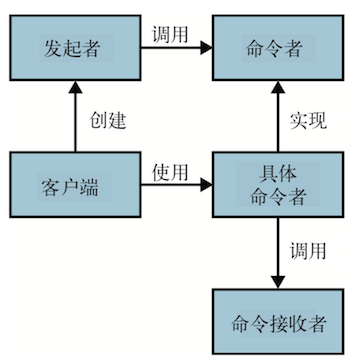
- 命令接收者:执行实际任务。
- 命令者:封装了所有调用命令执行者的信息。
- 发起者:控制一个或多个命令的顺序和执行。
- 客户端:创建具体的命令者实例。
看一个命令者模式的具体例子,看看如何使用 Lambda 表达式改进该模式。假设有一个 GUI Editor 组件,在上面可以执行 open、save 等一系列操作,如下图所示。现在我们想实现宏功能——也就是说,可以将一系列操作录制下来,日后作为一个操作执行,这就是我们的命令接收者。
- 文本编辑器可能具有的一般功能
public interface Editor {
public void save();
public void open();
public void close();
}
在该例子中,像 open、save 这样的操作称为命令,我们需要一个统一的接口来概括这些不同的操作,我将这个接口叫作 Action,它代表了一个操作。所有的命令都要实现该接口
- 所有操作均实现
Action接口
public interface Action {
public void perform();
}
现在让每个操作都实现该接口,这些类要做的只是在 Action 接口中调用 Editor 类中的一 个方法。我将遵循恰当的命名规范,用类名代表操作,比如 save 方法对应 Save 类。如下代码是定义好的命令对象。
- 保存操作代理给
Editor方法
public class Save implements Action {
private final Editor editor;
public Save(Editor editor) {
this.editor = editor;
}
@Override
public void perform() {
editor.save();
}
}
- 打开文件操作代理给
Editor方法
public class Open implements Action {
private final Editor editor;
public Open(Editor editor) {
this.editor = editor;
}
@Override
public void perform() {
editor.open();
}
}
现在可以实现 Macro 类了,该类 record 操作,然后一起运行。我们使用 List 保存操作序列,然后调用 forEach 方法按顺序执行每一个 Action 如下代码就是我们的命令发起者。
- 包含操作序列的宏,可按顺序执行操作
public class Macro {
private nal List<Action> actions;
public Macro() {
actions = new ArrayList<>();
}
public void record(Action action) {
actions.add(action);
}
public void run() {
actions.forEach(Action::perform);
}
}
在构建宏时,将每一个命令实例加入 Macro 对象的列表,然后运行宏,就会按顺序执行每一条命令。我是个“懒惰的”程序员,喜欢将通用的工作流定义成宏。我说“懒惰”了吗?我的意思其实是提高工作效率。如下代码展示了如何在用户代码中使用 Macro 对象。
- 使用命令者模式构建宏
Macro macro = new Macro();
macro.record(new Open(editor));
macro.record(new Save(editor));
macro.record(new Close(editor));
macro.run();
- 使用
Lambda表达式构建宏
Macro macro = new Macro();
macro.record(() -> editor.open());
macro.record(() -> editor.save());
macro.record(() -> editor.close());
macro.run();
事实上 ,如果意识到这些 Lambda 表达式的作用只是调用了一个方法,还能让问题变得更简单。我们可以使用方法引用将命令和宏对象关联起来(如下代码所示)。
Macro macro = new Macro();
macro.record(editor::open());
macro.record(editor::save());
macro.record(editor::close());
macro.run();
命令者模式只是一个可怜的程序员使用 Lambda 表达式的起点。使用 Lambda 表达式或是方法引用,能让代码更简洁,去除了大量样板代码,让代码意图更加明显。
宏只是使用命令者模式的一个例子,它被大量用在实现组件化的图形界面系统、撤销功能、线程池、事务和向导中。
在核心 Java 中,已经有一个和 Action 接口结构一致的函数接口——Runnable。 我们可以在实现上述宏程序中直接使用该接口,但在这个例子中,似乎 Action 是一个更符合我们待解问题的词汇,因此我们创建了自己的接口。
8.1.2 策略模式
策略模式能在运行时改变软件的算法行为。如何实现策略模式根据你的情况而定,但其主要思想是定义一个通用的问题,使用不同的算法来实现,然后将这些算法都封装在一个统一接口的背后。
文件压缩就是一个很好的例子。我们提供给用户各种压缩文件的方式,可以使用 zip 算法,也可以使用 gzip 算法,我们实现一个通用的 Compressor 类,能以任何一种算法压缩文件。
首先,为我们的策略定义 API(参见下图),我把它叫作 CompressionStrategy,每一种文件压缩算法都要实现该接口。该接口有一个 compress 方法,接受并返回一个 OutputStream 对象,返回的就是压缩后的 OutputStream(如下代码所示)。
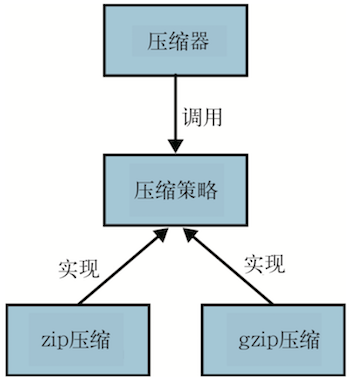
- 定义压缩数据的策略接口
public interface CompressionStrategy {
public OutputStream compress(OutputStream data) throws IOException;
}
我们有两个类实现了该接口,分别代表 gzip 和 ZIP 算法,使用 Java 内置的类实现 gzip 和 ZIP 算法。
- 使用
gzip算法压缩数据
public class GzipCompressionStrategy implements CompressionStrategy {
@Override
public OutputStream compress(OutputStream data) throws IOException {
return new GZIPOutputStream(data);
}
}
- 使用
zip算法压缩数据
public class ZipCompressionStrategy implements CompressionStrategy {
@Override
public OutputStream compress(OutputStream data) throws IOException {
return new ZipOutputStream(data);
}
}
现在可以动手实现 Compressor 类了,这里就是使用策略模式的地方。该类有一个 compress 方法,读入文件,压缩后输出。它的构造函数有一个 CompressionStrategy 参数,调用代 码可以在运行期使用该参数决定使用哪种压缩策略,比如,可以等待用户输入选择(如下代码所示)。
- 在构造类时提供压缩策略
public class Compressor {
private final CompressionStrategy strategy;
public Compressor(CompressionStrategy strategy) {
this.strategy = strategy;
}
public void compress(Path inFile, File outFile) throws IOException {
try (OutputStream outStream = new FileOutputStream(outFile)) {
Files.copy(inFile, strategy.compress(outStream));
}
}
}
如果使用这种传统的策略模式实现方式,可以编写客户代码创建一个新的 Compressor,并 且使用任何我们想要的策略(如下代码所示)。
- 使用具体的策略类初始化
Compressor
Compressor gzipCompressor = new Compressor(new GzipCompressionStrategy());
gzipCompressor.compress(inFile, outFile);
Compressor zipCompressor = new Compressor(new ZipCompressionStrategy());
zipCompressor.compress(inFile, outFile);
和前面讨论的命令者模式一样,使用 Lambda 表达式或者方法引用可以去掉样板代码。在这里,我们可以去掉具体的策略实现,使用一个方法实现算法,这里的算法由构造函数 中对应的 OutputStream 实现。使用这种方式,可以完全舍弃 GzipCompressionStrategy 和 ZipCompressionStrategy 类。如下代码展示了使用方法引用后的代码。
- 使用方法引用初始化 Compressor
Compressor gzipCompressor = new Compressor(GZIPOutputStream::new);
gzipCompressor.compress(inFile, outFile);
Compressor zipCompressor = new Compressor(ZipOutputStream::new);
zipCompressor.compress(inFile, outFile);
8.1.3 观察者模式
观察者模式是另一种可被 Lambda 表达式简化和改进的行为模式。在观察者模式中,被观察者持有一个观察者列表。当被观察者的状态发生改变,会通知观察者。观察者模式被大量应用于基于 MVC 的 GUI 工具中,以此让模型状态发生变化时,自动刷新视图模块,达到二者之间的解耦。
观看 GUI 模块自动刷新有点枯燥,我们要观察的对象是月球! NASA 和外星人都对登陆到月球上的东西感兴趣,都希望可以记录这些信息。NASA 希望确保阿波罗号上的航天员成功登月;外星人则希望在 NASA 注意力分散之时进犯地球。
让我们先来定义观察者的 API,这里我将观察者称作 LandingObserver。它只有一个 observeLanding 方法,当有东西登陆到月球上时会调用如下方法。
- 用于观察登陆到月球的组织的接口
public interface LandingObserver {
public void observeLanding(String name);
}
被观察者是月球 Moon,它持有一组 LandingObserver 实例,有东西着陆时会通知这些观察者,还可以增加新的 LandingObserver 实例观测 Moon 对象(如下代码)。
- Moon 类——当然不如现实世界中那么完美
public class Moon {
private final List<LandingObserver> observers = new ArrayList<>();
public void land(String name) {
for (LandingObserver observer : observers) {
observer.observeLanding(name);
}
}
public void startSpying(LandingObserver observer) {
observers.add(observer);
}
}
我们有两个具体的类实现了 LandingObserver 接口,分别代表外星人和 NASA 检测着陆情况。前面提到过,监测到登陆后它们有不同的反应。
- 外星人观察到人类登陆月球
public class Aliens implements LandingObserver {
@Override
public void observeLanding(String name) {
if (name.contains("Apollo")) {
System.out.println("They're distracted, lets invade earth!");
}
}
}
- NASA 也能观察到有人登陆月球
public class Nasa implements LandingObserver {
@Override
public void observeLanding(String name) {
if (name.contains("Apollo")) {
System.out.println("We made it!");
}
}
}
和前面的模式类似,在传统的例子中,用户代码需要有一层模板类,如果使用 Lambda 表达式,就不用编写这些类了(如下代码所示)。
- 使用类的方式构建用户代码
Moon moon = new Moon();
moon.startSpying(new Nasa());
moon.startSpying(new Aliens());
moon.land("An asteroid");
moon.land("Apollo 11");
- 使用 Lambda 表达式构建用户代码
Moon moon = new Moon();
moon.startSpying(name -> {
if (name.contains("Apollo"))
System.out.println("We made it!");
});
moon.startSpying(name -> {
if (name.contains("Apollo"))
System.out.println("They're distracted, lets invade earth!");
});
moon.land("An asteroid");
moon.land("Apollo 11");
还有一点值得思考,无论使用观察者模式或策略模式,实现时采用 Lambda 表达式还是传 统的类,取决于策略和观察者代码的复杂度。我这里所举的例子代码很简单,只是一两个 方法调用,很适合展示新的语言特性。然而在有些情况下,观察者本身就是一个很复杂的类,这时将很多代码塞进一个方法中会大大降低代码的可读性。
从某种角度来说,将大量代码塞进一个方法会让可读性变差是决定如何使用 Lambda 表达式的黄金法则。之所以不在这里过分强调,是因为这也是编写一般方法时的黄金法则!
8.1.4 模板方法模式
开发软件时一个常见的情况是有一个通用的算法,只是步骤上略有不同。我们希望不同的实现能够遵守通用模式,保证它们使用了同一个算法,也是为了让代码更加易读。一旦你从整体上理解了算法,就能更容易理解其各种实现。
模板方法模式是为这些情况设计的:整体算法的设计是一个抽象类,它有一系列抽象方法,代表算法中可被定制的步骤,同时这个类中包含了一些通用代码。算法的每一个变种由具体的类实现,它们重写了抽象方法,提供了相应的实现。
让我们假想一个情境来搞明白这是怎么回事。假设我们是一家银行,需要对公众、公司和 职员放贷。放贷程序大体一致——验明身份、信用记录和收入记录。这些信息来源不一, 衡量标准也不一样。你可以查看一个家庭的账单来核对个人身份;公司都在官方机构注册过,比如美国的 SEC、英国的 Companies House。
我们先使用一个抽象类 LoanApplication 来控制算法结构,该类包含一些贷款调查结果报告的通用代码。根据不同的申请人,有不同的类:CompanyLoanApplication、Personal LoanApplication 和 EmployeeLoanApplication。如下代码展示了 LoanApplication 类的结构。
- 使用模板方法模式描述申请贷款过程
public abstract class LoanApplication {
public void checkLoanApplication() throws ApplicationDenied {
checkIdentity();
checkCreditHistory();
checkIncomeHistory();
reportFindings();
}
protected abstract void checkIdentity() throws ApplicationDenied;
protected abstract void checkIncomeHistory() throws ApplicationDenied;
protected abstract void checkCreditHistory() throws ApplicationDenied;
private void reportFindings(){}
}
CompanyLoanApplication 的 checkIdentity 方法在 Companies House 等注册公司数据库中 查找相关信息。checkIncomeHistory 方法评估公司的现有利润、损益表和资产负债表。 checkCreditHistory 方法则查看现有的坏账和未偿债务。
PersonalLoanApplication 的 checkIdentity 方法通过分析客户提供的纸本结算单,确认客户地址是否真实有效。checkIncomeHistory 方法通过检查工资条判断客户是否仍被雇佣。 checkCreditHistory 方法则会将工作交给外部的信用卡支付提供商。
EmployeeLoanApplication 就是没有查阅员工历史功能的 PersonalLoanApplication。为了方便起见,我们的银行在雇佣员工时会查阅所有员工的收入记录(如下代码)。
- 员工申请贷款是个人申请的一种特殊情况
public class EmployeeLoanApplication extends PersonalLoanApplication {
@Override
protected void checkIncomeHistory() {
// 这是自己人 !
}
}
使用 Lambda 表达式和方法引用,我们能换个角度思考模板方法模式,实现方式也跟以前不一样。模板方法模式真正要做的是将一组方法调用按一定顺序组织起来。如果用函数接口表示函数,用 Lambda 表达式或者方法引用实现这些接口,相比使用继承构建算法,就会得到极大的灵活性。让我们看看如何使用这种方式实现 LoanApplication 算法,请看如下代码!
- 员工申请贷款的例子
public class LoanApplication {
private final Criteria identity;
private final Criteria creditHistory;
private final Criteria incomeHistory;
public LoanApplication(Criteria identity, Criteria creditHistory,
Criteria incomeHistory) {
this.identity = identity;
this.creditHistory = creditHistory;
this.incomeHistory = incomeHistory;
}
public void checkLoanApplication() throws ApplicationDenied {
identity.check();
creditHistory.check();
incomeHistory.check();
reportFindings();
}
private void reportFindings(){}
}
正如读者所见,这里没有使用一系列的抽象方法,而是多出一些属性:identity、 creditHistory 和 incomeHistory。每一个属性都实现了函数接口 Criteria,该接口检查一 项标准,如果不达标就抛出一个问题域里的异常。我们也可以选择从 check 方法返回一个 类来表示成功或失败,但是沿用异常更加符合先前的实现(如下所示)。
- 如果申请失败,函数接口 Criteria 抛出异常
public interface Criteria {
public void check() throws ApplicationDenied;
}
采用这种方式,而不是基于继承的模式的好处是不需要在 LoanApplication 及其子类中实现算法,分配功能时有了更大的灵活性。比如,我们想让 Company 类负责所有的检查,那么 Company 类就会多出一系列方法,如下代码所示。
- Company 类中的检查方法
public void checkIdentity() throws ApplicationDenied;
public void checkProfitAndLoss() throws ApplicationDenied;
public void checkHistoricalDebt() throws ApplicationDenied;
现在只需为 CompanyLoanApplication 类传入对应的方法引用,如下代码所示。
CompanyLoanApplication类声明了对应的检查方法
public class CompanyLoanApplication extends LoanApplication {
public CompanyLoanApplication(Company company) {
super(company::checkIdentity,
company::checkHistoricalDebt,
company::checkProfitAndLoss);
}
}
将行为分配给 Company 类的原因是各个国家之间确认公司信息的方式不同。在英国, Companies House 规范了注册公司信息的地址,但在美国,各个州的政策是不一样的。
使用函数接口实现检查方法并没有排除继承的方式。我们可以显式地在这些类中使用 Lambda 表达式或者方法引用。
我们也不需要强制 EmployeeLoanApplication 继承 PersonalLoanApplication 来达到复用, 可以对同一个方法传递引用。它们之间是否天然存在继承关系取决于员工的借贷是否是普通人借贷这种特殊情况,或者是另外一种不同类型的借贷。因此,使用这种方式能让我们更加紧密地为问题建模。
8.2 使用Lambda表达式的领域专用语言
领域专用语言(DSL)是针对软件系统中某特定部分的编程语言。它们通常比较小巧,表达能力也不如 Java 这样能应对大多数编程任务的通用语言强。DSL 高度专用:不求面面俱到,但求有所专长。
人们通常将 DSL 分为两类:内部 DSL 和外部 DSL。外部 DSL 脱离程序源码编写,然后单独解析和实现。比如级联样式表(CSS)和正则表达式,就是常用的外部 DSL。
内部 DSL 嵌入编写它们的编程语言中。如果读者使用过 JMock 和 Mockito 等模拟类库,或用过 SQL 构建 API,如 JOOQ 或 Querydsl,那么就知道什么是内部 DSL。从某种角度上说,内部 DSL 就是普通的类库,提供 API 方便使用。虽然简单,内部 DSL 却功能强大,让你的代码 变得更加精炼、易读。理想情况下,使用 DSL 编写的代码读起来就像描述问题所使用的语言。
有了 Lambda 表达式,实现 DSL 就更简单了,那些想尝试 DSL 的程序员又多了一件趁手的工具。我们将通过实现一个用于行为驱动开发(BDD)的 DSL:LambdaBehave,来探 索其中遇到的各种问题。
BDD 是测试驱动开发(TDD)的一个变种,它的重点是描述程序的行为,而非一组需要通过的单元测试。我们的设计灵感源于一个叫Jasmine的JavaScript BDD框架,前端开发中会大量使用该框架。如下展示了如何使用 Jasmine 创建测试用例。
- Jasmine
describe("A suite is just a function", function() {
it("and so is a spec", function() {
var a = true; expect(a).toBe(true);
});
});
如果读者不熟悉 JavaScript,阅读这段代码可能会稍感疑惑。下面我们使用Java 8实现一 个类似的框架时会一步一步来,只需要记住,在 JavaScript 中我们使用 function() { ... } 来表示 Lambda 表达式。
让我们分别来看看这些概念:
- 每一个规则描述了程序的一种行为;
- 期望是描述应用行为的一种方式,在规则中定义;
- 多个规则合在一起,形成一个套件。
这些概念在传统的测试框架,比如 JUnit 中,都有对应的概念。规则对应一个测试方法, 期望对应断言,套件对应一个测试类。
8.2.1 使用Java编写DSL
让我们先看一下实现后的 Java BDD 框架长什么样子,例 8-28 描述了一个 Stack 的某些行为。
- 描述
Stack的案例
public class StackSpec {{
describe("a stack", it -> {
it.should("be empty when created", expect -> {
expect.that(new Stack()).isEmpty();
});
it.should("push new elements onto the top of the stack", expect -> {
Stack<Integer> stack = new Stack<>();
stack.push(1);
expect.that(stack.get(0)).isEqualTo(1);
});
it.should("pop the last element pushed onto the stack", expect -> {
Stack<Integer> stack = new Stack<>();
stack.push(2);
stack.push(1);
expect.that(stack.pop()).isEqualTo(2);
});
});
}}
首先我们使用动词 describe 为套件起头,然后定义一个名字表明这是描述什么东西的行 为,这里我们使用了 "a stack"。
每一条规则读起来尽可能接近英语中的句子。它们均以 it.should 打头,其中 it 指正在描述的对象。然后用一句简单的英语描述行为,最后使用 expect.that 做前缀,描述期待的行为。
检查规则时,会从命令行得到一个简单的报告,表明是否有规则失败。你会发现 pop 操作期望 的返回值是 2,而不是 1,因此“pop the last element pushed onto the stack”这条规则就失败了:
```java
a stack
should pop the last element pushed onto the stack[expected: but was: ] should be empty when created
should push new elements onto the top of the stack
```
8.2.2 实现
读者已经领略了使用 Lambda 表达式的 DSL 所带来的便利,现在该看看我们是如何实现该框架的。我们希望会让大家看到,自己实现一个这样的框架是多么简单。
描述行为首先看到的是 describe 这个动词,简单导入一个静态方法就够了。为套件创建一 个 Description 实例,在此处理各种各样的规则。Description 类就是我们定义的 DSL 中 的 it(如下代码)。
- 从
describe方法开始定义规则
public static void describe(String name, Suite behavior){
Description description = new Description(name);
behavior.specifySuite(description);
}
每个套件的规则描述由用户使用一个 Lambda 表达式实现,因此我们需要一个 Suite 函数接口来表示规则组成的套件,如下代码所示。该接口接收一个 Description 对象作为参数,我们在 describe 方法里将其传入。
- 每个测试套件都由一个实现该接口的
Lambda表达式实现
public interface Suite {
void specifySuite(Description description);
}
在我们定义的 DSL 中,不仅套件由 Lambda 表达式实现,每一条规则也是一个 Lambda 表达式。它们也需要定义一个函数接口:Specification(如下代码所示)。示例代码中的 expect 变量是 Expect 类的实例,我们稍后描述:
public interface Specification {
void specifyBehaviour(Expect expect);
}
之前来回传递的 Description 实例这里就派上用场了。我们希望用户可以使用 it.should 命名他们的规则,这就是说 Description 类需要有一个 should 方法(如下代码所示)。这里是真正做事的地方,该方法通过调用 specifySuite 执行 Lambda 表达式。如果规则失败,会 抛出一个标准的 Java AssertionError,而其他任何 Throwable 对象则认为是一个错误:
- 将用
Lambda表达式表示的规则传入should方法
public void should(String description, Specification specification) {
try {
Expect expect = new Expect();
specification.specifyBehaviour(expect);
Runner.current.recordSuccess(suite, description);
} catch (AssertionError cause) {
Runner.current.recordFailure(suite, description, cause);
} catch (Throwable cause) {
Runner.current.recordError(suite, description, cause);
}
}
规则通过 expect.that 描述期望的行为,也就是说 Expect 类需要一个 that 方法供用户调 用,如下代码所示。这里可以封装传入的对象,然后暴露一些常用的方法,如 isEqualTo。 如果规则失败,抛出相应的断言。
- 期望链的开始
public final class Expect {
public BoundExpectation that(Object value) {
return new BoundExpectation(value);
}
// 省去类定义的其他部分
}
读者可能会注意到,我一直忽略了一个细节,该细节与 Lambda 表达式无关。StackSpec 类 并没有直接实现任何方法,我直接将代码写在里边。这里我偷了个懒,在类定义的开头和结尾使用了双括号:
public class StackSpec {{
...
}}
这其实是一个匿名构造函数,可以执行任意的 Java 代码块,所以这等价于一个完整的构造函数,只是少了一些样板代码。这段代码也可以写作:
public class StackSpec {
public StackSpec() {
...
}
}
要实现一个完整的 BDD 框架还有很多工作要做,本节只是为了向读者展示如何使用 Lambda 表达式创建领域专用语言。我在这里讲解了与 DSL 中 Lambda 表达式交互的部分, 以期能帮助读者管中窥豹,了解如何实现这种类型的 DSL。
8.2.3 评估
流畅性的一方面表现在 DSL 是否是 IDE 友好的。换句话说,你只需记住少量知识,然后用代码自动补全功能补齐代码。这就是使用 Description 和 Expect 对象的原因。当然也可以导入静态方法 it 或 expect,一些 DSL 中就使用了这种方式。如果选择向 Lambda 表达 式传入对象,而不是导入一个静态方法,就能让 IDE 的使用者轻松补全代码。
用户唯一要记住的是调用 describe 方法,这种方式的好处通过单纯阅读可能无法体会,我建议大家创建一个示例项目,亲自体验这个框架。
另一个值得注意的是大多数测试框架提供了大量注释,或者很多外部“魔法”,或者借助 于反射。我们不需要这些技巧,就能直接使用 Lambda 表达式在 DSL 中表达行为,就和使 用普通的 Java 方法一样。
8.3 使用Lambda表达式的SOLID原则
SOLID 原则是设计面向对象程序时的一些基本原则。原则的名字是个简写,分别代表了
下面五个词的首字母:Single responsibility、Open/closed、Liskov substitution``、Interface segregation 和 Dependency inversion。这些原则能指导你开发出易于维护和扩展的代码。
每种原则都对应着一系列潜在的代码异味,并为其提供了解决方案。有很多图书介绍这个主题,因此我不会详细讲解,而是关注如何在 Lambda 表达式的环境下应用其中的三条原则。在 Java 8 中,有些原则通过扩展,已经超出了原来的限制。
8.3.1 单一功能原则
程序中的类或方法只能有一个改变的理由。
软件开发中不可避免的情况是需求的改变。这可能是需要增加新功能,也可能是你对问题 的理解或者客户发生变化了,或者你想变得更快,总之,软件会随着时间不断演进。
当软件的需求发生变化,实现这些功能的类和方法也需要变化。如果你的类有多个功能,一个功能引发的代码变化会影响该类的其他功能。这可能会引入缺陷,还会影响代码演进的能力。
让我们看一个简单的示例程序,该程序由资产列表生成 BalanceSheet 表格,然后输出成一份 PDF 格式的报告。如果实现时将制表和输出功能都放进同一个类,那么该类就有两个变化的理由。你可能想改变输出功能,输出不同的格式,比如 HTML,可能还想改变 BalanceSheet 的细节。这为将问题分解成两个类提供了很好的理由:一个负责将 BalanceSheet 生成表格,一个负责输出。
单一功能原则不止于此:一个类不仅要功能单一,而且还需将功能封装好。换句话说,如果我想改变输出格式,那么只需改动负责输出的类,而不必关心负责制表的类。
这是强内聚性设计的一部分。说一个类是内聚的,是指它的方法和属性需要统一对待,因为它们紧密相关。如果你试着将一个内聚的类拆分,可能会得到刚才创建的那两个类。
既然你已经知道了什么是单一功能原则,问题来了:这和 Lambda 表达式有什么关系?
Lambda 表达式在方法级别能更容易实现单一功能原则。让我们看一个例子,该段程序能得出一定范围内有多少个质数(如下代码)。
- 计算质数个数,一个方法里塞进了多重职责
public long countPrimes(int upTo) {
long tally = 0;
for (int i = 1; i < upTo; i++) {
boolean isPrime = true;
for (int j = 2; j < i; j++) {
if (i % j == 0) {
isPrime = false;
}
}
if (isPrime) {
tally++;
}
}
return tally;
}
很显然,在上面的例子中我们同时干了两件事:计数和判断一个数是否是质数。在例下面的代码中, 通过简单重构,将两个功能一分为二。
- 将
isPrime重构成另外一个方法后,计算质数个数的方法
public long countPrimes(int upTo) {
long tally = 0;
for (int i = 1; i < upTo; i++) {
if (isPrime(i)) {
tally++;
}
}
return tally;
}
private boolean isPrime(int number) {
for (int i = 2; i < number; i++) {
if (number % i == 0) {
return false;
}
}
return true;
}
但我们的代码还是有两个功能。代码中的大部分都在对数字循环,如果我们遵守单一功能 原则,那么迭代过程应该封装起来。改进代码还有一个现实的原因,如果需要对一个很大 的 upTo 计数,我们希望可以并行操作。没错,线程模型也是代码的职责之一!
我们可以使用 Java 8 的集合流(如下代码所示)重构上述代码,将循环操作交给类库本身处理。这里使用了 range 方法从 0 至 upTo 计数,然后 filter 出质数,最后对结果做 count。
- 使用集合流重构质数计数程序
public long countPrimes(int upTo) {
return IntStream.range(1, upTo)
.filter(this::isPrime) .count();
}
private boolean isPrime(int number) {
return IntStream.range(2, number)
.allMatch(x -> (number % x) != 0);
}
如果我们想利用更多 CPU 加速计数操作,可使用 parallelStream 方法,而不需要修改任何其他代码(如例下代码所示)。
- 并行运行基于集合流的质数计数程序
public long countPrimes(int upTo) {
return IntStream.range(1, upTo)
.parallel()
.filter(this::isPrime) .count();
}
private boolean isPrime(int number) {
return IntStream.range(2, number)
.allMatch(x -> (number % x) != 0);
}
因此,利用高阶函数,可以轻松帮助我们实现功能单一原则。
8.3.2 开闭原则
软件应该对扩展开放,对修改闭合。 —— Bertrand Meyer
开闭原则的首要目标和单一功能原则类似:让软件易于修改。一个新增功能或一处改动, 会影响整个代码,容易引入新的缺陷。开闭原则保证已有的类在不修改内部实现的基础上可扩展,这样就努力避免了上述问题。
第一次听说开闭原则时,感觉有点痴人说梦。不改变实现怎么能扩展一个类的功能呢?答案是借助于抽象,可插入新的功能。让我们看一个具体的例子。
我们要写的程序用来衡量系统性能,并且把得到的结果绘制成图形。比如,我们有描述计 算机花在用户空间、内核空间和输入输出上的时间散点图。我将负责显示这些指标的类叫 作 MetricDataGraph。
设计 MetricDataGraph 类的方法之一是将代理收集到的各项指标放入该类,该类的公开 API 如下代码所示。
- MetricDataGraph 类的公开 API
class MetricDataGraph {
public void updateUserTime(int value);
public void updateSystemTime(int value);
public void updateIoTime(int value);
}
但这样的设计意味着每次想往散点图中添加新的时间点,都要修改 MetricDataGraph 类。通过引入抽象可以解决这个问题,我们使用一个新类 TimeSeries 来表示各种时间点。这时, MetricDataGraph 类的公开 API 就得以简化,不必依赖于某项具体指标,如下代码所示。
- MetricDataGraph 类简化之后的 API
class MetricDataGraph {
public void addTimeSeries(TimeSeries values); }
每项具体指标现在可以实现 TimeSeries 接口,在需要时能直接插入。比如,我们可能会有如下类:UserTimeSeries、SystemTimeSeries 和 IoTimeSeries。 如果要添加的,比如由于虚拟化所浪费的 CPU 时间,则可增加一个新的实现了 TimeSeries 接口的类: StealTimeSeries。这样,就扩展了 MetricDataGraph 类,但并没有修改它。
高阶函数也展示出了同样的特性:对扩展开放,对修改闭合。前面提到的 ThreadLocal 类 就是一个很好的例子。ThreadLocal 有一个特殊的变量,每个线程都有一个该变量的副本 并与之交互。该类的静态方法 withInitial 是一个高阶函数,传入一个负责生成初始值的 Lambda 表达式。
这符合开闭原则,因为不用修改 ThreadLocal 类,就能得到新的行为。给 withInitial 方法传入不同的工厂方法,就能得到拥有不同行为的 ThreadLocal 实例。比如,可以使用 ThreadLocal 生成一个 DateFormatter 实例,该实例是线程安全的,如下代码所示。
- ThreadLocal 日期格式化器
// 实现
ThreadLocal<DateFormat> localFormatter = ThreadLocal.withInitial(() -> new SimpleDateFormat());
// 使用
DateFormat formatter = localFormatter.get();
通过传入不同的 Lambda 表达式,可以得到完全不同的行为。比如在下面代码中,我们为每个 Java 线程创建了唯一、有序的标识符。
- ThreadLocal 标识符
// 或者这样实现
AtomicInteger threadId = new AtomicInteger();
ThreadLocal<Integer> localId
= ThreadLocal.withInitial(() -> threadId.getAndIncrement());
// 使用
int idForThisThread = localId.get();
对开闭原则的另外一种理解和传统的思维不同,那就是使用不可变对象实现开闭原则。不可变对象是指一经创建就不能改变的对象。
不可变性”一词有两种解释:观测不可变性和实现不可变性。观测不可变性是指在其他对象看来,该类是不可变的;实现不可变性是指对象本身不可变。实现不可变性意味着观测不可变性,反之则不一定成立。
java.lang.String 宣称是不可变的,但事实上只是观测不可变,因为它在第一次调用 hashCode 方法时缓存了生成的散列值。在其他类看来,这是完全安全的,它们看不出散列值是每次在构造函数中计算出来的,还是从缓存中返回的。
之所以在这样一本讲解 Lambda 表达式的书中谈及不可变对象,是因为它们都是函数式编程中耳熟能详的概念,这里也是 Lambda 表达式的发源地。它们生来就符合我在本书中讲述的编程风格。
我们说不可变对象实现了开闭原则,是因为它们的内部状态无法改变,可以安全地为其增加新的方法。新增加的方法无法改变对象的内部状态,因此对修改是闭合的;但它们又增加了新的行为,因此对扩展是开放的。当然,你还需留意不要改变程序其他部分的状态。
因其天生线程安全的特性,不可变对象引起了人们的格外注意。它们没有内部状态可变, 因此可以安全地在不同线程之间共享。
如果我们回顾这几种方式,会发现已经偏离了传统的开闭原则。事实上,在 Bertrand Meyer 第一次引入这个原则时,原意是一旦实现后,类就不允许改动了。在现代敏捷开发环境中,完成一个类的说法很明显已经过时了。业务需求和使用方法的变化可能会让一个类的功能和当初设计的不同。当然这不成为忽视这一原则的理由,只是说明了所谓的原则只应作为指导,而不应教条地全盘接受,走向极端。
我认为还有一点值得思考,在Java 8中,使用抽象插入多个类,或者使用高阶函数来实现开闭原则其实是一样的。因为抽象需要使用一个接口或抽象类来定义方法,这其实就是一 种多态的使用方式。
在 Java 8 中,任何传入高阶函数的 Lambda 表达式都由一个函数接口表示,高阶函数负责调用其唯一的方法,根据传入 Lambda 表达式的不同,行为也不同。这其实也是在用多态来实现开闭原则。
8.3.3 依赖反转原则
抽象不应依赖细节,细节应该依赖抽象。
让程序变得死板、脆弱、难于改变的方法之一是将上层业务逻辑和底层粘合模块的代码混在一起,因为这两样东西都会随着时间发生变化。
依赖反转原则的目的是让程序员脱离底层粘合代码,编写上层业务逻辑代码。这就让上层代码依赖于底层细节的抽象,从而可以重用上层代码。这种模块化和重用方式是双向的: 既可以替换不同的细节重用上层代码,也可以替换不同的业务逻辑重用细节的实现。
让我们看一个具体的、自动化构建地址簿的例子,实现时使用了依赖反转原则达到上层的解耦。该应用以电子卡片作为输入,使用某种存储机制编写地址簿。
显然,我们可将代码分成如下三个基本模块:
- 一个能解析电子卡片格式的电子卡片阅读器;
- 能将地址存为文本文件的地址簿存储模块;
- 从电子卡片中获取有效信息并将其写入地址簿的编写模块。
我们用如下图来表示各模块之间的关系。
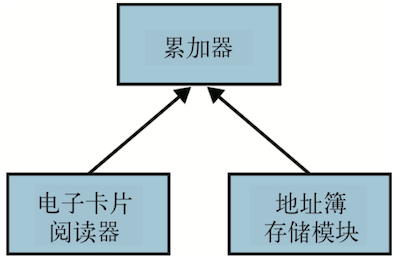
在该系统中,重用编写模块很复杂,但是电子卡片阅读器和地址簿存储模块都不依赖于其他模块,因此很容易在其他系统中重用。还可以替换它们,比如用一个其他的阅读器,或者从人们的 Twitter 账户信息中读取内容;又比如我们不想将地址簿存为一个文本文件, 而是使用数据库存储等其他形式。
为了具备能在系统中替换组件的灵活性,必须保证编写模块不依赖阅读器或存储模块的实现细节。因此我们引入了对阅读信息和输出信息的抽象,编写模块的实现依赖于这种抽象。在运行时传入具体的实现细节,这就是依赖反转原则的工作原理(简单理解为细节要依赖抽象,抽象不依赖细节)。
具体到 Lambda 表达式,我们之前遇到的很多高阶函数都符合依赖反转原则。比如 map 函 数重用了在两个集合之间转换的代码。map 函数不依赖于转换的细节,而是依赖于抽象的概念。在这里,就是依赖函数接口:Function。(接口可认为是抽象的,因为接口不包含实现细节,当然 Java8 接口可以有默认实现)
资源管理是依赖反转的另一个更为复杂的例子。显然,可管理的资源很多,比如数据库连接、线程池、文件和网络连接。这里我将以文件为例,因为文件是一种相对简单的资源, 但是背后的原则可以很容易应用到更复杂的资源中。
让我们看一段代码,该段代码从一种假想的标记语言中提取标题,其中标题以冒号( :)结尾。我们的方法先读取文件,逐行检查,滤出标题,然后关闭文件。我们还将和读写文 件有关的异常封装成接近待解决问题的异常:HeadingLookupException,最后的代码如下代码所示:
- 解析文件中的标题
public List<String> findHeadings(Reader input) {
try (BufferedReader reader = new BufferedReader(input)) {
return reader.lines()
.filter(line -> line.endsWith(":"))
.map(line -> line.substring(0, line.length() - 1))
.collect(toList());
} catch (IOException e) {
throw new HeadingLookupException(e);
}
}
可惜,我们的代码将提取标题和资源管理、文件处理混在一起。我们真正想要的是编写提取标题的代码,而将操作文件相关的细节交给另一个方法。可以使用 Stream<String> 作为抽象,让代码依赖它,而不是文件。Stream 对象更安全,而且不容易被滥用。我们还想传 入一个函数,在读文件出问题时,可以创建一个问题域里的异常。整个过程如下所示,而且我们将问题域里的异常处理和资源管理的异常处理分开了。
- 剥离了文件处理功能后的业务逻辑
public List<String> findHeadings(Reader input) { return withLinesOf(input,
lines -> lines.filter(line -> line.endsWith(":"))
.map(line -> line.substring(0, line.length()-1))
.collect(toList()),
HeadingLookupException::new);
}
是不是想知道 withLinesOf 方法是什么样的?请看如下代码
- 定义 withLinesOf 方法
private <T> T withLinesOf(Reader input, Function<Stream<String>, T> handler,
Function<IOException, RuntimeException> error) {
try (BufferedReader reader = new BufferedReader(input)) { return handler.apply(reader.lines());
} catch (IOException e) { throw error.apply(e);
} }
withLinesOf 方法接受一个 Reader 参数处理文件读写,然后将其封装进一个 Buffered-Reader 对象,这样就可以逐行读取文件了。handler 函数代表了我们想在该方法中执行的代码,它以文件中的每一行组成的 Stream 作为参数。另一个参数是 error,输入输出有异常时会调用该方法,它会构建出与问题域有关的异常,出问题时就抛出该异常。
总结下来,高阶函数提供了反转控制,这就是依赖反转的一种形式,可以很容易地和 Lambda 表达式一起使用。依赖反转原则另外值得注意的一点是待依赖的抽象不必是接口。 这里我们使用 Stream 对原始的 Reader 和文件处理做抽象,这种方式也适用于函数式编程 语言中的资源管理——通常使用高阶函数管理资源,接受一个回调函数使用打开的资源, 然后再关闭资源。事实上,如果Java 7就有Lambda表达式,那么Java 7中的try-with-resources 功能可能只需要一个库函数就能实现。
8.4 进阶阅读
本章讨论的很多内容都涉及了更广泛的设计问题,关注程序整体,而不是一个方法。限于本书讨论的重点是 Lambda 表达式,我们对这些话题的讨论都是浅尝辄止。如果读者想了 解更多细节,可参考相关图书。
长期以来,“Bob 大叔”是 SOLID 原则的推动者,他撰写了大量有关该主题的文章和书籍, 也多次就该主题举行过演讲。如果你想免费从他那里获取一些相关知识,可访问 Object Mentor 官方网站(http://www.objectmentor.com/resources/publishedArticles.html),在“设计 模式”主题下有一系列详述设计原则的文章。
如果你想深入理解领域专用语言,包括内部领域专用语言和外部领域专用语言,推荐大家 阅读Martin Fowler和Rebecca Parsons合著的Domain-Speci c Languages
8.5 要点回顾
Lambda表达式能让很多现有设计模式更简单、可读性更强,尤其是命令者模式。- 在
Java8中,创建领域专用语言有更多的灵活性。- - 在
Java8中,有应用SOLID原则的新机会。
本文由 zealzhangz 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2018/11/25 19:07
