第 9 章 使用Lambda表达式编写并发程序
前面讨论了如何并行化处理数据,本章讨论如何使用 Lambda 表达式编写并发应用,高效传递信息和非阻塞式 I/O。
9.1 为什么要使用非阻塞式I/O
在介绍并行化处理时,讲了很多关于如何高效利用多核 CPU 的内容。这种方式很管用,但在处理大量数据时,它并不是唯一可用的线程模型。
假设要编写一个支持大量用户的聊天程序。每当用户连接到聊天服务器时,都要和服务器建立一个 TCP 连接。使用传统的线程模型,每次向用户写数据时,都要调用一个方法向用户传输数据,这个方法会阻塞当前线程。
这种 I/O 方式叫阻塞式 I/O,是一种通用且易于理解的方式,因为和程序用户的交互通常符合这样一种顺序执行的方式。缺点是,将系统扩展至支持大量用户时,需要和服务器建立大量 TCP 连接,因此扩展性不是很好。
非阻塞式 I/O,有时也叫异步 I/O,可以处理大量并发网络连接,而且一个线程可以为多个连接服务。和阻塞式 I/O 不同,对聊天程序客户端的读写调用立即返回,真正的读写操作则在另一个独立的线程执行,这样就可以同时执行其他任务了。如何使用这些省下来的CPU 周期完全取决于程序员,可以选择读入更多数据,也可以玩一局 Minecraft 游戏。
到目前为止,我避免使用代码来描述这两种 I/O 方式,因为根据 API 的不同,它们有多种实现方式。Java 标准类库的 NIO 提供了非阻塞式 I/O 的接口,NIO 的最初版本用到了 Selector 的概念,让一个线程管理多个通信管道,比如向客户端写数据的网络套接字。
然而这种方式压根儿就没有在 Java 程序员中流行起来,它编写出来的代码难于理解和调试。引入 Lambda 表达式后,设计和实现没有这些缺点的 API 就顺手多了。
9.2 回调
为了展示非阻塞式 I/O 的原则,我们将运行一个极其简单的聊天应用,没有那些花里胡哨的功能。当用户第一次连接应用时,需要设定用户名,随后便可通过应用收发信息。
我们将使用 Vert.x 框架实现该应用,并且在实施过程中根据需要,引入其他一些必需的技术。让我们先来写一段接收 TCP 连接的代码,如下代码所示。
- 接收 TCP 连接
public class MainVerticle extends AbstractVerticle {
@Override
public void start(Future<Void> startFuture) throws Exception {
vertx.createHttpServer().requestHandler(req -> {
req.response()
.putHeader("content-type", "text/plain")
.end("Hello from Vert.x!");
}).listen(8080, http -> {
if (http.succeeded()) {
startFuture.complete();
System.out.println("HTTP server started on http://localhost:8080");
} else {
startFuture.fail(http.cause());
}
});
}
}
读者可将 Verticle 想成 Servlet —— 它是 Vert.x 框架中部署的原子单元。上述代码的入口是 start 方法,它和普通 Java 程序中的 main 方法类似。在聊天应用中,我们用它建立一 个接收 TCP 连接的服务器。
然后向 requestHandler 方法输入一个 Lambda 表达式,每当有用户连接到聊天应用时,都会调用该 Lambda 表达式。这就是一个回调,与在第 1 章中介绍的 Swing 中的回调类似。 这种方式的好处是,应用不必控制线程模型 —— Vert.x 框架为我们管理线程,打理好了一切相关复杂性,程序员只需考虑事件和回调就够了。
我们的应用还通过 dataHandler 方法注册了另外一个回调,每当从网络套接字读取数据时,该回调就会被调用。在本例中,我们希望提供更复杂的功能,因此没有使用 Lambda 表达式, 而是传入一个常规的 User 类,该类实现了相关的函数接口。User 类的定义如下代码所示。
- 处理用户连接
public class User implements Handler<Buffer> {
private static final Pattern newline = Pattern.compile("\\n");
private final NetSocket socket;
private nal Set<String> names;
private nal EventBus eventBus;
private Optional<String> name;
public User(NetSocket socket, Verticle verticle) {
Vertx vertx = verticle.getVertx();
this.socket = socket;
names = vertx.sharedData().getSet("names");
eventBus = vertx.eventBus();
name = Optional.empty();
}
@Override
public void handle(Buffer buffer) {
newline.splitAsStream(buffer.toString())
.forEach(line -> {
if (!name.isPresent())
setName(line);
else
handleMessage(line);
});
}
// Class continues...
变量 buffer 包含了网络连接写入的数据,我们使用的是一个分行的文本协议,因此需要先将其转换成一个字符串,然后依换行符分割。
这里使用了正则表达式 java.util.regex.Pattern 的一个实例 newline 来匹配换行符。尤为方便的是,Java 8 为Pattern 类新增了一个 splitAsStream 方法,该方法使用正则表达式将字符串分割好后,生成一个包含分割结果的流对象。
用户连上聊天服务器后,首先要做的事是设置用户名。如果用户名未知,则执行设置用户名的逻辑;否则正常处理聊天消息。
还需要接收来自其他用户的消息,并且将它们传递给聊天程序客户端,让接收者能够读取 消息。为了实现该功能,在设置当前用户用户名的同时,我们注册了另外一个回调,用来写入消息
- 注册聊天消息
eventBus.registerHandler(name, (Message<String> msg) -> {
sendClient(msg.body());
});
上述代码使用了 Vert.x 的事件总线,它允许在 verticle 对象之间以非阻塞式 I/O 的方式传递消息(如下图所示)。registerHandler 方法将一个处理程序和一个地址关联,有消息发送给该地址时,就将之作为参数传递给处理程序,并且自动调用处理程序。这里使用用户名作为地址。
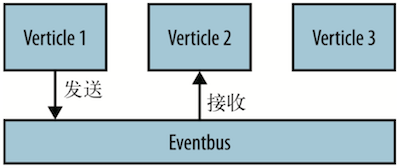
通过为地址注册处理程序并发消息的方式,可以构建非常复杂和解耦的服务,它们之间完全以非阻塞式 I/O 方式响应。需要注意的是,在我们的设计中没有共享状态。
Vert.x 的事件总线允许发送多种类型的消息,但是它们都要使用 Message 对象进行封装。 点对点的消息传递由 Message 对象本身完成,它们可能持有消息发送方的应答处理程序。 在这种情况下,我们想要的是消息体,也就是文字本身,则只需调用 body 方法。我们通过将消息写入 TCP 连接,把消息发送给了用户聊天客户端。
当应用想要把消息从一个用户发送给另一个用户时,就使用代表另一个用户的地址(如下代码所示),这里使用了用户的用户名。
- 发送聊天信息
eventBus.send(user, name.get() +‘>’+ message);
让我们扩展这个基础聊天服务器,向关注你的用户群发消息,为此,需要实现两个新命令。
- 代表群发命令的感叹号,它能将信息群发给关注你的用户。如果Bob键入“!hello followers”,则所有关注 Bob 的用户都会收到该条信息:“Bob>hello followers”。
- 关注命令,用来关注一个用户,比如“followBob”。
一旦解析了命令,就可以着手实现
broadcastMessage和followUser方法,它们分别代表了这两个命令。
这里的通信模式略有不同,除了给单个用户发消息,现在还拥有了群发信息的能力。幸好,Vert.x 的事件总线允许我们将一条信息发布给多个处理程序(见下图),让我们得以沿用一种类似的方式。
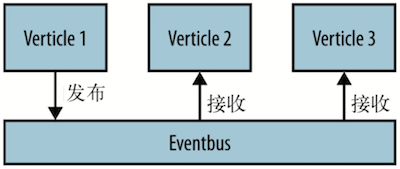
代码的唯一变化是使用了事件总线的 publish 方法,而不是先前的 send 方法。为了避免用户使用 ! 命令时和已有的地址冲突,在用户名后紧跟 .followers。比如 Bob 发布一条消息 时,所有注册到 bob.followers 的处理程序都会收到消息(如下代码所示)。
- 向关注者群发消息
private void broadcastMessage(String message) {
String name = this.name.get();
eventBus.publish(name + ".followers", name +‘>’+ message);
}
在处理程序里,我们希望和早先的操作一样:将消息传递给客户
- 接收群发的消息
private void followUser(String user) {
eventBus.registerHandler(user + ".followers", (Message<String> message) -> {
sendClient(message.body());
});
}
如果将消息发送到有多个处理程序监听的地址,则会轮询决定哪个处理程序会接收到消息。这意味着在注册地址时要多加小心。
9.3 消息传递架构
这里我们要讨论的是一种基于消息传递的架构,我用它实现了一个简单的聊天客户端。聊天客户端的细节并不重要,重要的是这个模式,那就让我们来谈谈消息传递本身吧。
首先要注意的是我们的设计里不共享任何状态。verticle 对象之间通过向事件总线发送消 息通信,这就是说我们不需要保护任何共享状态,因此根本不需要在代码中添加锁或使用 synchronized 关键字,编写并发程序变得更加简单。
为了确保不在 verticle 对象之间共享状态,我们对事件总线上传递的消息做了某些限制。例子中使用的消息是普通的 Java 字符串,它们天生就是不可变的,因此可以安全地在 verticle 对象之间传递。 接收处理程序无法改变 String 对象的状态,因此不会和消息发送者互相干扰。
Vert.x 没有限制只能使用字符串传递消息,我们可以使用更复杂的 JSON 对象,甚至使用 Buffer 类构建自己的消息。这些消息是可变的,也就是说如果使用不当,消息发送者和接收者可以通过读写消息共享状态。
Vert.x 框架通过在发送消息时复制消息的方式来避免这种问题。这样既保证接收者得到了正确的结果,又不会共享状态。无论是否使用 Vert.x,确保消息不会共享状态都是最重要的。不可变消息是最简单的解决方式,但通过复制消息也能解决该问题。
使用 verticle 对象模型开发的并发系统易于测试,因为每个 verticle 对象都可以通过发送消息、验证返回值的方式单独测试。然后使用这些经过测试的模块组合成一个复杂系统,而不用担心使用共享的可变状态通信在集成时会遇到大量问题。当然,点对点的测试还是必须的,确保系统和预期的行为一致。
基于消息传递的系统让隔离错误变得简单,也便于编写可靠的代码。如果一个消息处理程序发生错误,可以选择重启本地 verticle 对象,而不用去重启整个 JVM。
在第 6 章中,我们看到了如何使用 Lambda 表达式和 Stream 类库编写并行处理数据代码。 并行机制让处理海量数据的速度更快,消息传递和稍后将会介绍的响应式编程是问题的另 一面:我们希望在有限的并行运行的线程里,执行更多的 I/O 操作,比如连接更多的聊天客户端。无论哪种情况,解决方案都是一样的:使用 Lambda 表达式表示行为,构建 API 来管理并发。聪明的类库意味着简单的应用代码。
9.4 末日金字塔
读者已经看到了如何使用回调和事件编写非阻塞的并发代码,但是我还没提起房间里的大象。如果编写代码时使用了大量的回调,代码会变得难于阅读,即便使用了 Lambda 表达式也是如此。让我们通过一个具体例子来更好地理解这个问题。
在编写聊天程序服务器端代码时,我写了很多测试,从客户端的角度描述了 verticle 对象 的行为。如下代码中的 messageFriend 测试所示:
- 检测聊天服务器上两个朋友是否能发消息的测试
@Test
public void messageFriend() {
withModule(() -> {
withConnection(richard -> {
richard.dataHandler(data -> {
assertEquals("bob>oh its you!", data.toString());
moduleTestComplete();
});
richard.write("richard\n");
withConnection(bob -> {
bob.dataHandler(data -> {
assertEquals("richard>hai", data.toString());
bob.write("richard<oh its you!");
});
bob.write("bob\n");
vertx.setTimer(6, id -> richard.write("bob<hai"));
});
});
});
}
我连上两个客户端,分别是 Richard 和 Bob,Richard 对 Bob 说“嗨”,Bob 回答“哦,是 你啊”。我已经将建立连接的通用代码重构,即使这样,读者依然会注意到那些嵌套的回调形成了一个末日金字塔。代码不断地向屏幕右方挤过去,就像一座金字塔。(别看我,这名字又不是我起的!)这是一个众所周知的反模式,让代码难于阅读和理解。同时,将代码的逻辑分散在了多个方法里。
上一章我们讨论过如何通过将一个 Lambda 表达式传给 with 方法的方式来管理资源。读者会注意到,在测试代码中我多次用到了该方法。withModule 方法部署 Vert.x 模块,运行一 些代码然后关闭模块。还有一个 withConnection 方法连接到 ChatVerticle,使用完毕后关掉连接。
这里使用 with 方法,而不使用 try-with-resources 的方式,好处是它符合本章我们使用的非阻塞线程模型。我们可以重构代码,让它变得易于理解,如下代码所示。
- 分成多个方法后的测试代码,测试聊天服务器上两个朋友是否能发消息
@Test
public void canMessageFriend() {
withModule(this::messageFriendWithModule);
}
private void messageFriendWithModule() {
withConnection(richard -> {
checkBobReplies(richard);
richard.write("richard\n");
messageBob(richard);
});
}
private void messageBob(NetSocket richard) {
withConnection(messageBobWithConnection(richard));
}
private Handler<NetSocket> messageBobWithConnection(NetSocket richard) {
return bob -> {
checkRichardMessagedYou(bob);
bob.write("bob\n");
vertx.setTimer(6, id -> richard.write("bob<hai"));
};
}
private void checkRichardMessagedYou(NetSocket bob) {
bob.dataHandler(data -> {
assertEquals("richard>hai", data.toString());
bob.write("richard<oh its you!");
});
}
private void checkBobReplies(NetSocket richard) {
richard.dataHandler(data -> {
assertEquals("bob>oh its you!", data.toString());
moduleTestComplete();
});
}
上面的代码中的重构将测试逻辑分散在了多个方法里,解决了末日金字塔问题。不再是一个方 法只能有一个功能,我们将一个功能分散在了多个方法里!代码还是难于阅读,不过这次换了一个方式。
想要链接或组合的操作越多,问题就会越严重,我们需要一个更好的解决方案。
9.5 Future
构建复杂并行操作的另外一种方案是使用 Future。Future 像一张欠条,方法不是返回一个值,而是返回一个 Future 对象,该对象第一次创建时没有值,但以后能拿它“换回”一个值。
调用 Future 对象的 get 方法获取值,它会阻塞当前线程,直到返回值。可惜,和回调一样,组合 Future 对象时也有问题,我们会快速浏览这些可能碰到的问题。
我们要考虑的场景是从外部网站查找某专辑的信息。我们需要找出专辑上的曲目列表和艺术家,还要保证有足够的权限访问登录等各项服务,或者至少确保已经登录。
如下代码使用 Future API 解决了该问题。在 ① 处登录提供曲目和艺术家信息的服务,这时会 返回一个 Future<Credentials> 对象,该对象包含登录信息。Future 接口支持泛型,可将 Future<Credentials> 看作是 Credentials 对象的一张欠条。
@Override
public Album lookupByName(String albumName) {
Future<Credentials> trackLogin = loginTo("track");①
Future<Credentials> artistLogin = loginTo("artist");
try {
Future<List<Track>> tracks = lookupTracks(albumName, trackLogin.get());②
Future<List<Artist>> artists = lookupArtists(albumName, artistLogin.get());
return new Album(albumName, tracks.get(), artists.get()); ③
} catch (InterruptedException | ExecutionException e) {
throw new AlbumLookupException(e.getCause()); ④
}
}
在 ② 处使用登录后的凭证查询曲目和艺术家信息,通过调用 Future 对象的 get 方法获取凭证信息。在 ③ 处构建待返回的专辑对象,这里同样调用 get 方法以阻塞 Future 对象。如果有异常,我们在 ④ 处将其转化为一个待解问题域内的异常,然后将其抛出。
读者将会看到,如果要将 Future 对象的结果传给其他任务,会阻塞当前线程的执行。这会成为一个性能问题,任务不是平行执行了,而是(意外地)串行执行。
以上面的例子来说,这意味着在登录两个服务之前,我们无法启动任何查找任务。没必要这样: lookupTracks 只需要自己的登录凭证,lookupArtists 也是一样。我们将理想的行为用如下图描述出来。
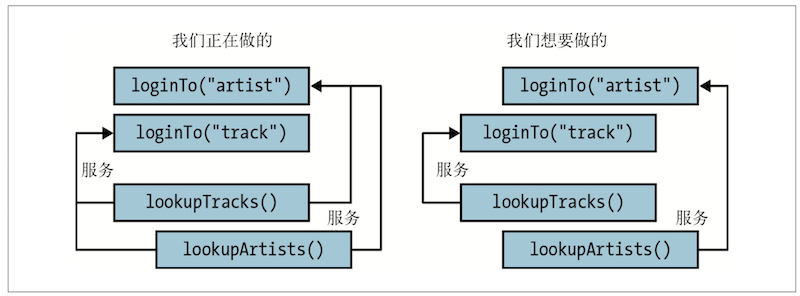 查询操作不必等待所有登录操作完成后才能执行
查询操作不必等待所有登录操作完成后才能执行
可以将对 get 的调用放到 lookupTracks 和 lookupArtists 方法的中间,这能解决问题,但是代码丑陋,而且无法在多次调用之间重用登录凭证。
我们真正需要的是不必调用 get 方法阻塞当前线程,就能操作 Future 对象返回的结果。我们需要将 Future 和回调结合起来使用。
9.6 CompletableFuture
这些问题的解决之道是 CompletableFuture,它结合了 Future 对象打欠条的主意和使用回调处理事件驱动的任务。其要点是可以组合不同的实例,而不用担心末日金字塔问题。
你以前可能接触过 CompletableFuture 对象背后的概念,在其他语言中这被 叫作延迟对象或约定。在Google Guava类库和Spring框架中,这被叫作 ListenableFutures。
在如下代码中,我会使用 CompletableFuture 重写上面的例子来展示它的用法。
- 使用
CompletableFuture从外部网站下载专辑信息
public Album lookupByName(String albumName) {
CompletableFuture<List<Artist>> artistLookup = loginTo("artist")
.thenCompose(artistLogin -> lookupArtists(albumName, artistLogin)); ①
return loginTo("track")
.thenCompose(trackLogin -> lookupTracks(albumName, trackLogin))②
.thenCombine(artistLookup, (tracks, artists)
-> new Album(albumName, tracks, artists)) ③
.join(); ④
}
在上面的代码中,loginTo、lookupArtists 和 lookupTracks 方 法 均 返 回 CompletableFuture , 而不是 Future。CompletableFuture API 的技巧是注册 Lambda 表达式,并且把高阶函数链接起来。方法不同,但道理和 Stream API 的设计是相通的。
在 ① 处使用 thenCompose 方法将 Credentials 对象转换成包含艺术家信息的 CompletableFuture 对象,这就像和朋友借了点钱,然后在亚马逊上花了。你不会马上拿到新买的书——亚马逊会发给你一封电子邮件,告诉你新书正在运送途中,又是一张欠条!
在 ② 处还是使用了 thenCompose 方法,通过登录 Track API,将 Credentials 对象转换成包 含曲目信息的 CompletableFuture 对象。这里引入了一个新方法 thenCombine ③,该方法将一个 CompletableFuture 对象的结果和另一个 CompletableFuture 对象组合起来。组合操作是由用户提供的 Lambda 表达式完成,这里我们要使用曲目信息和艺术家信息构建一个 Album 对象。
这时我有必要提醒大家,和使用 Stream API 一样,现在还没真正开始做事呢,只是定义好了做事的规则。在调用最终的方法之前,无法保证 CompletableFuture 对象已经生成结果。CompletableFuture 对象实现了 Future 接口,可以调用 get 方法获取值。 CompletableFuture 对象包含 join 方法,我们在 ④ 处调用了该方法,它的作用和 get 方法 是一样的,而且它没有使用 get 方法时令人倒胃口的检查异常。
读者现在可能已经掌握了使用 CompletableFuture 的基础,但是如何创建它们又是另外一 回事。创建 CompletableFuture 对象分两部分:创建对象和传给它欠客户代码的值。
如下代码所示,创建 CompletableFuture 对象非常简单,调用它的构造函数就够了。现在就可以将该对象传给客户代码,用来将操作链接在一起。我们同时保留了对该对象的引用,以便在另一个线程里继续执行任务。
- 为
Future提供值
CompletableFuture<Artist> createFuture(String id) {
CompletableFuture<Artist> future = new CompletableFuture<>();
startJob(future);
return future;
}
一旦任务完成,不管是在哪个线程里执行的,都需要告诉 CompletableFuture 对象那个值, 这份工作可以由各种线程模型完成。比如,可以 submit 一个任务给 ExecutorService,或 者使用类似 Vert.x 这样基于事件循环的系统,或者直接启动一个线程来执行任务。在如下例子中,为了告诉 CompletableFuture 对象值已就绪,需要调用 complete 方法,是时候还债了,如下图所示。
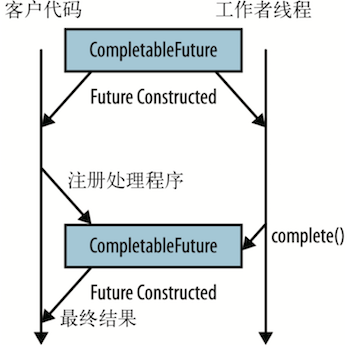
一个可完成的 Future 是一张可以被处理的欠条
当然,CompletableFuture 的常用情境之一是异步执行一段代码,该段代码计算并返回一个值。为了避免大家重复实现同样的代码,有一个工厂方法 supplyAsync,用来创建 CompletableFuture 实例,如下例子所示。
- 异步创建 CompletableFuture 实例的示例代码
CompletableFuture<Track> lookupTrack(String id) {
return CompletableFuture.supplyAsync(() -> {
// 这里会做一些繁重的工作 ①
// ...
return track; //②
}, service)//③
}
supplyAsync 方法接受一个 Supplier 对象作为参数,然后执行它。如 ① 处所示,这里的要点是能执行一些耗时的任务,同时不会阻塞当前线程——这就是方法名中 Async 的含义。② 处的返回值用来完成 CompletableFuture。在 ③ 处我们提供了一个叫作 service 的 Executor,告诉 CompletableFuture 对象在哪里执行任务。如果没有提供 Executor,就会使 用相同的 fork/join 线程池并行执行。
当然,不是所有的欠条都能兑现。有时候碰上异常,我们无力偿还,如下代码所示, CompletableFuture 为此提供了 completeExceptionally,用于处理异常情况。该方法可以视作 complete 方法的备选项,但不能同时调用 complete 和 completeExceptionally 方法。
- 出现错误时完成 Future
future.completeExceptionally(new AlbumLookupException("Unable to find " + name));
完整讨论 CompletableFuture 接口已经超出了本章的范围,很多时候它是一个隐藏大礼包。 该接口有很多有用的方法,可以用你想到的任何方式组合 CompletableFuture 实例。现在, 读者应该能熟练地使用高阶函数链接各种操作,告诉计算机应该做什么了吧
让我们简单看一下其中的一些用例。
- 如果你想在链的末端执行一些代码而不返回任何值,比如
Consumer和Runnable,那就 看看thenAccept和thenRun方法。 - 可使用
thenApply方法转换CompletableFuture对象的值,有点像使用Stream的map方法。 - 在
CompletableFuture对象出现异常时,可使用exceptionally方法恢复,可以将一个函数注册到该方法,返回一个替代值。 - 如果你想有一个
map,包含异常情况和正常情况,请使用handle方法。 - 要找出
CompletableFuture对象到底出了什么问题,可使用isDone和isCompleted-Exceptionally方法辅助调查。
CompletableFuture 对于处理并发任务非常有用,但这并不是唯一的办法。下面要学习的概念提供了更多的灵活性,但是代码也更复杂。
9.7 响应式编程
CompletableFuture 背后的概念可以从单一的返回值推广到数据流,这就是响应式编程。响应式编程其实是一种声明式编程方法,它让程序员以自动流动的变化和数据流来编程。
你可以将电子表格想象成一个使用响应式编程的例子。如果在单元格 C1 中键入 =B1+5,其实是在告诉电子表格将 B1 中的值加 5,然后将结果存入 C1。而且,将来 B1 中的值变化后,电子表格会自动刷新 C1 中的值。
RxJava 类库将这种响应式的理念移植到了JVM。我们这里不会深入类库,只描述其中的一些关键概念。RxJava 类库引入了一个叫作 Observable 的类,该类代表了一组待响应的事件,可以理解为一沓欠条。在 Observable 对象和第 3 章讲述的 Stream 接口之间有很强的关联。
两种情况下,都需要使用 Lambda 表达式将行为和一般的操作关联、都需要将高阶函数链 接起来定义完成任务的规则。实际上,Observable 定义的很多操作都和 Stream 的相同: map、filter、reduce。
最大的不同在于用例。Stream 是为构建内存中集合的计算流程而设计的,而 RxJava 则是为了组合异步和基于事件的系统流程而设计的。它没有取数据,而是把数据放进去。换个角度理解 RxJava,它是处理一组值,而 CompletableFuture 用来处理一个值。
这次的例子是查找艺术家,如下代码所示。search 方法根据名字和国籍过滤结果,它在本地缓存了一份艺术家名单,但必须从外部服务上查询艺术家信息,比如国籍。
- 通过名字和国籍查找艺术家
public Observable<Artist> search(String searchedName,
String searchedNationality,
int maxResults) {
return getSavedArtists() ①
.filter(name -> name.contains(searchedName)) ②
.flatMap(this::lookupArtist) ③
.filter(artist -> artist.getNationality() ④
.contains(searchedNationality))
.take(maxResults); ⑤
}
在 ① 处取得一个包含艺术家姓名的 Observable 对象,该对象的高阶函数和 Stream 类似,在②和③处使用姓名和国籍做过滤,和使用 Stream 是一样的。
在 ④ 处将姓名替换为一个 Artist 对象,如果这只是调用构造函数这么简单,我们显然会使用 map 操作。但这里我们需要组合调用一系列外部服务,每种服务都可能在它自己的线程或线程池里执行。因此,我们将名字替换为 Observable 对象,来表示一个或多个艺术家,因此使用了 flatMap 操作。
我们还需要在查找时限定返回结果的最大值:maxResults,在 ⑤ 处,我们通过调用 Observable 对象的 take 方法来实现该功能。
读者会发现,这个 API 很像使用 Stream。它和 Stream 的最大区别是:Stream 是为了计算最终结果,而 RxJava 在线程模型上则像 CompletableFuture。
使用 CompletableFuture 时,我们通过给 complete 方法一个值来偿还欠条。而 Observable 代表了一个事件流,我们需要有能力传入多个值,如下代码展示了该怎么做。
- 给
Observable对象传值,并且完成它
observer.onNext("a");
observer.onNext("b");
observer.onNext("c");
observer.onCompleted();
我们不停地调用 onNext 方法,Observable 对象中的每个值都调用一次。这可以在一个循环里做,也可以在任何我们想要生成值的线程里做。一旦完成了产生事件的工作,就调 用 onCompleted 方法表示任务完成。和使用 Stream 一样,也有一些静态工厂方法用来从 Future、迭代器和数组中创建 Observable 对象。
和 CompletableFuture 类似,Observable 也能处理异常。如果出现错误,调用 onError 方 法,如下代码所示。这里的功能和 CompletableFuture 略有不同——你能得到异常发生之前所有的事件,但两种情况下,只能正常或异常地终结程序,两者只能选其一。
- 通知
Observable对象有错误发生
observer.onError(new Exception());
和介绍 CompletableFuture 时一样,这里只给出了如何使用和在什么地方使用 Observable 的一点建议。读者如果想了解跟多细节,请阅读项目文档(https://github.com/ReactiveX/ RxJava/wiki/Getting-Started)。RxJava 已经开始集成进 Java 类库的生态系统,比如企业 级的集成框架 Apache Camel 已经加入了一个叫作 [Camel-RX](http://camel.apache.org/ rx.html) 的模块,该模块使得可以在该框架中使用 RxJava。Vert.x 项目也启动了一个 Rx-ify 它的 API 项目。
9.8 何时何地使用新技术
本章讲解了如何使用非阻塞式和基于事件驱动的系统。这是否意味着大家明天就要扔掉现有的Java EE 或者 Spring 企业级 Web 应用呢?答案当然是否定的。
即使不去考虑 CompletableFuture 和 RxJava 相对较新,使用它们依然有一定的复杂度。它们用起来比到处显式使用 Future 和回调简单,但对很多问题来说,传统的阻塞式 Web 应 用开发技术就足够了。如果还能用,就别修理。
当然,我也不是说阅读本章会白白浪费您一个美好的下午。事件驱动和响应式应用正在变得越来越流行,而且经常会是为你的问题建模的最好方式之一。响应式编程宣言(http:// www.reactivemanifesto.org/)鼓励大家使用这种方式编写更多应用,如果它适合你的待解问 题,那么就应该使用。相比阻塞式设计,有两种情况可能特别适合使用响应式或事件驱动的方式来思考。
第一种情况是业务逻辑本身就使用事件来描述。Twitter 就是一个经典例子。Twitter 是一种订阅文字流信息的服务,用户彼此之间推送信息。使用事件驱动架构编写应用,能准确地为业务建模。图形化展示股票价格可能是另一个例子,每一次价格的变动都可认为是一个事件。
另一种显然的用例是应用需要同时处理大量 I/O 操作。阻塞式 I/O 需要同时使用大量线程, 这会导致大量锁之间的竞争和太多的上下文切换。如果想要处理成千上万的连接,非阻塞式 I/O 通常是更好的选择。
9.9 要点回顾
- 使用基于
Lambda表达式的回调,很容易实现事件驱动架构。 CompletableFuture代表了IOU,使用Lambda表达式能方便地组合、合并。Observable继承了CompletableFuture的概念,用来处理数据流。
本文由 zealzhangz 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为:
2019/02/14 20:38
